Research
My research focuses on developing general and scalable approaches for real-world perception, reasoning, and action.
I’m broadly interested in physical intelligence, including topics such as 3D motion, video perception & generation and robot
action generation. Recently, I’m excited about leveraging foundation models for grounded interaction and action policy
learning.
|
News
-
2026.06
Our paper JointHOI is accepted to ECCV 2026!
-
2026.03
Our paper Pri4R is out — a spatiotemporally-aware VLA that learns world dynamics via 4D privileged supervision.
-
2025.09
I joined LG AI Research, Physical Intelligence Lab as a Research Scientist Intern, working on robotics using VLAs.
-
2025.06
Our papers V.I.P. and DisCoRD are accepted to ICCV 2025.
|
Publications
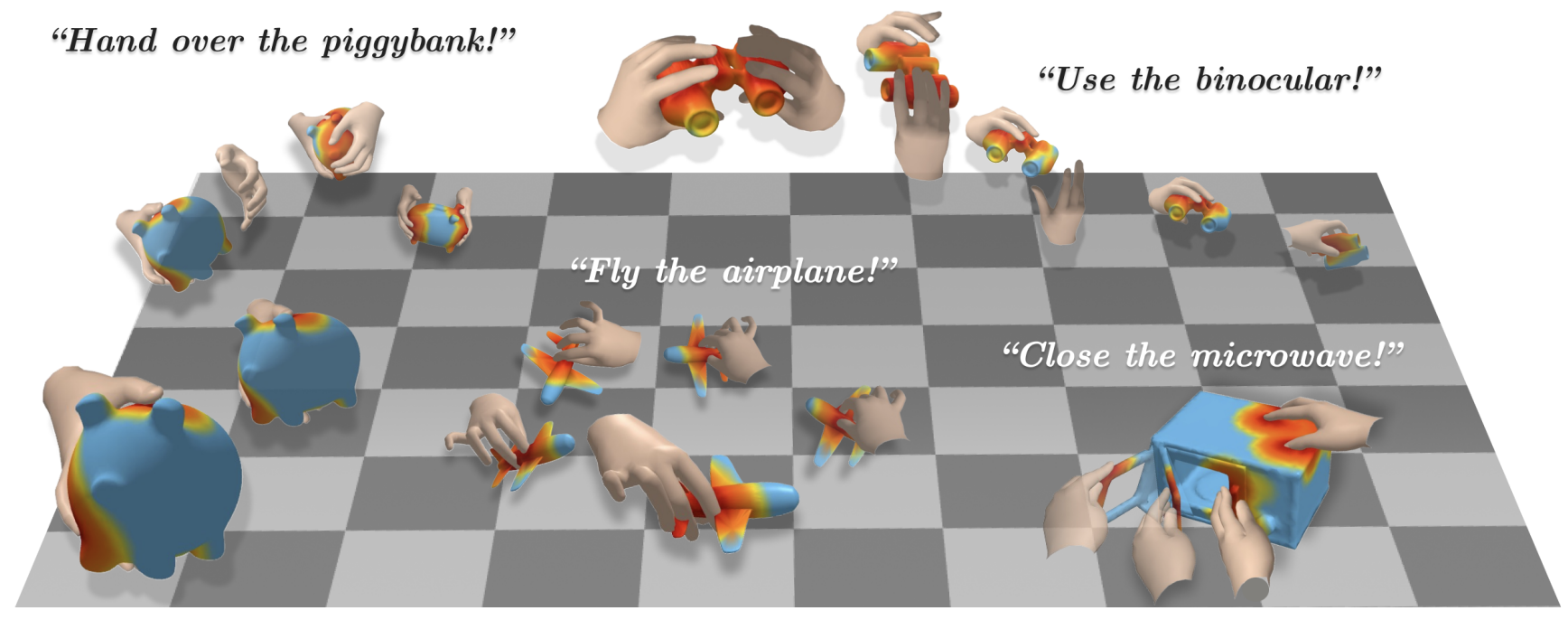
JointHOI: Jointly Generating Contact Maps Enhances Hand Object Interaction Generation
Mingyeong Song, Jungbin Cho, Jisoo Kim, Ananya Bal, Kartik Sharma, Youngjae Yu, László A. Jeni, Junhyug Noh
ECCV, 2026
TL;DR We show that jointly generating contact maps together with the interaction substantially enhances hand–object interaction generation.
arXiv
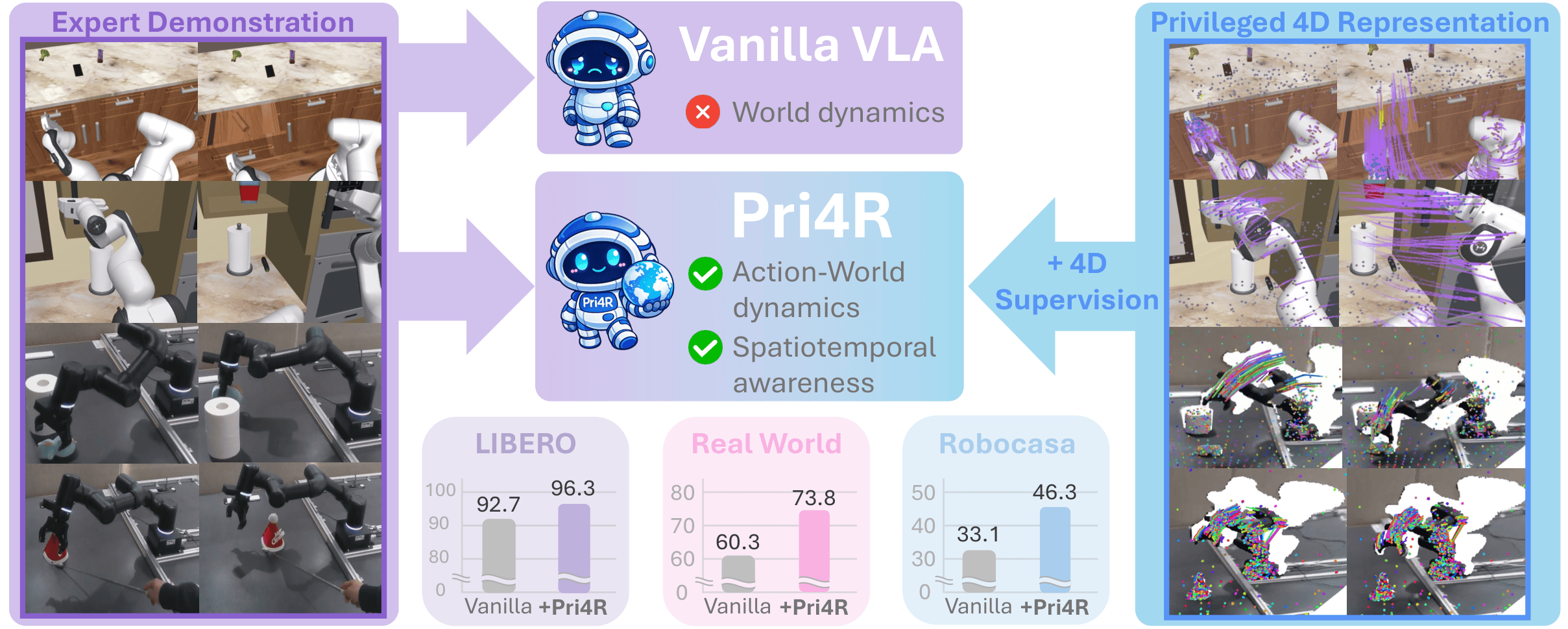
Pri4R: Learning World Dynamics for Vision-Language-Action Models with Privileged 4D Representation
Jisoo Kim*, Jungbin Cho*, Sanghyeok Chu, Ananya Bal, Jinhyung Kim, Gunhee Lee, Sihaeng Lee, Seung Hwan Kim, Bohyung Han, Hyunmin Lee, Laszlo A. Jeni, Seungryong Kim
Arxiv, 2026
TL;DR We equip vision-language-action models with implicit awareness of action–world dynamics via privileged 4D geometric supervision, using point tracking as an auxiliary objective that adds no inference overhead.
project page /
arXiv

SceneAdapt: Scene-aware Adaptation of Human Motion Diffusion
Jungbing Cho*, Minsu Kim*, Jisoo Kim, Ce Zheng, László A. Jeni, Ming-Hsuan Yang, Youngjae Yu, Seon Joo Kim
Arxiv, 2025
TL;DR We introduce a two-stage adaptation framework that injects geometric scene constraints into text-to-motion generation — using motion inbetweening as a bridge — without any paired text–scene–motion data.
project page /
arXiv

V.I.P: Iterative Online Preference Distillation for Efficient Video Diffusion Models
Jisoo Kim, Wooseok Seo, Junwan Kim, Seungho Park, Sooyeon Park, Youngjae Yu
ICCV, 2025
TL;DR We integrate DPO and SFT losses for distillation to build an efficient video diffusion model, with an automatic pair-curation pipeline, and outperform the teacher using only synthetic data generated from the teacher itself.
project page /
arXiv

DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding
Jungbin Cho *, Junwan Kim *, Jisoo Kim, Minseo Kim, Mingu Kang, Seuneun Hong, Tae-Hyun Oh, Youngjae Yu
ICCV, 2025 [Highlight]
TL;DR We use rectified flow to decode discrete motion tokens directly in continuous motion space, framing token decoding as conditional generation to produce smoother, more natural motion while staying faithful to the conditioning.
arXiv

Speaking Beyond Language: A Large-Scale Multimodal Dataset for Learning Nonverbal Cues from Video-Grounded Dialogues
Youngmin Kim *, Jiwan Chung *, Jisoo Kim, Sunghyun Lee, Sangkyu Lee, Junhyeok Kim, Cheoljong Yang, Youngjae Yu
ACL main, 2025
TL;DR We introduce VENUS, a large-scale multimodal dataset for learning nonverbal cues from video-grounded dialogues.
arXiv
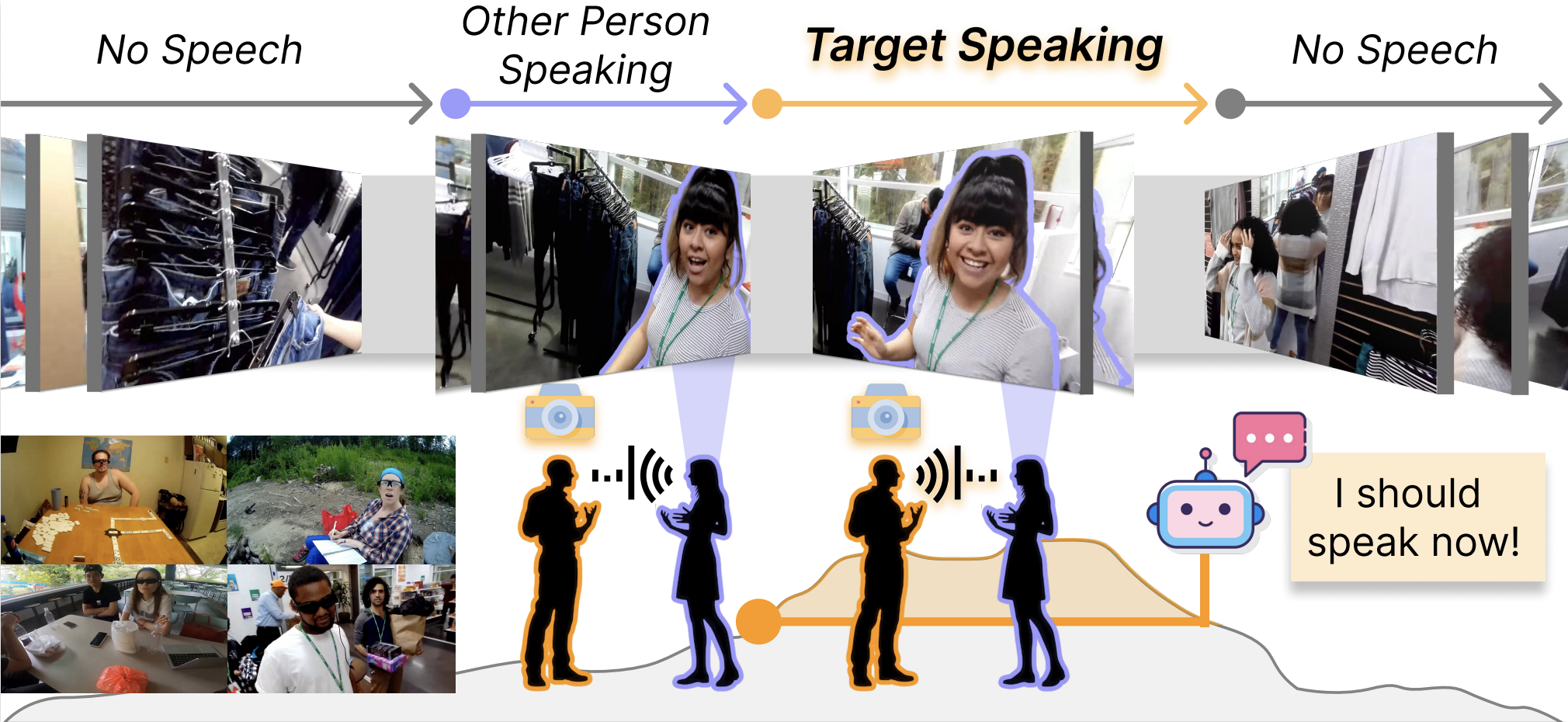
EgoSpeak: Learning When to Speak for Egocentric Conversational Agents in the Wild
Junhyeok Kim, Min Soo Kim, Jiwan Chung, Jungbin Cho, Jisoo Kim, Sungwoong Kim, Gyeongbo Sim, Youngjae Yu
NAACL Findings, 2025
TL;DR We introduce a framework for real-time, first-person prediction of when to start speaking from egocentric streaming video, together with YT-Conversation, an in-the-wild pretraining dataset.
arXiv
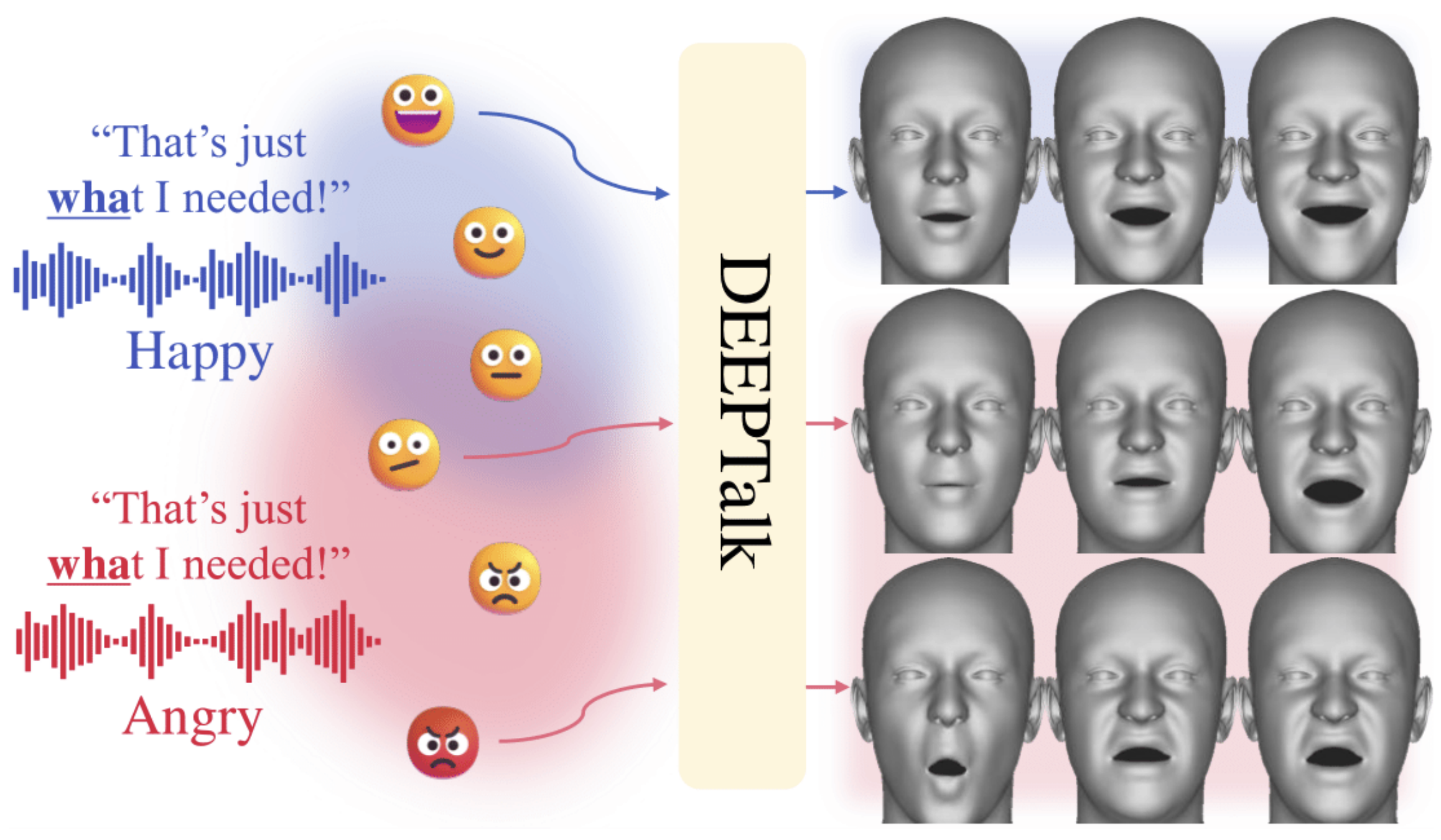
DEEPTalk: Dynamic Emotion Embedding for Probabilistic Speech-Driven 3D Face Animation
Jisoo Kim *, Jungbin Cho *, Joonho Park, Soonmin Hwang, DaEun Kim, Geon Kim, Youngjae Yu
AAAI, 2025
TL;DR We generate diverse, emotionally rich speech-driven 3D facial animation by learning a probabilistic joint emotion embedding (DEE) and a temporally hierarchical VQ-VAE motion prior.
project page /
arXiv
|
